 AnCrypt v1.038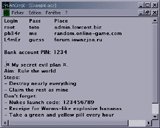
AnCrypt is a Notepad-like text editor which crypts the edited files (BlowFish 448bit algorithm).
It can be used to carry confidential data on an USB key. Encrypting a text file enables you to keep its content safe. Typical
uses of this program would be to store passwords you can't remember, or other
important information you wouldn't want other people to see.
Specially designed to be small and easy to move around, this program has nearly
the same interface as the default Windows notepad. It doesn't require any installation,
and allows you for example to bring it along with your sensitive data on a floppy or an USB key.
This program relies only on encryption to protect your data, and does not offer
any protection against other attacks like memory dump, window text copy, screenshot
analysis, clipboard hijacking, swap file access, keylogger, ...
If you suspect you are in an hostile environment, do not open your encrypted file.
This program was created at the start of the century and generates keys which are relatively cheap to break. It only remains available to allow previous users to decrypt their files and move on to something else.
It should no longer be considered to offer a good enough security for the current environment.
For any serious use, prefer using a modern password manager (Ex: KeePass, Password Safe, ...).
Downloads: [ Win98/Me ] [ Win2k/XP/2003 ] |
 AnFV v1.0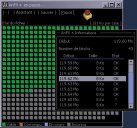
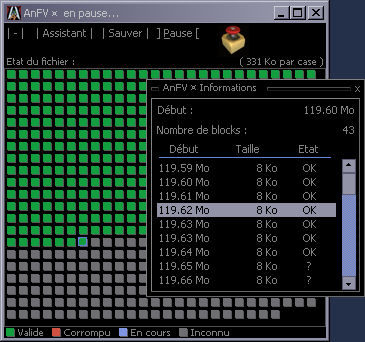
AnFV enables you to perform advanced integrity check on files.
Unlike many other similar softwares, AnFV pinpoints the location and extent
of one or more erroneous blocks in a checked file. The easiest way to check that a file is the same as an original is
certainly to compare it byte by byte to the original. However, when the original
is not available on site, for example in the case of a downloaded file, it is
impossible to do so without having to download it once again. In this case, the
most widespread method to check that a file is not corrupted is to compute a kind
of magical number for the original file, and to compare it to the one computed for
the downloaded one.
This kind of computation is called hashing, and the magical number is a hashcode.
There are plenty of ways to hash data, amongst which we find the well-known CRC-32,
MD5 and SHA1. If the hashcodes obtained on two blocks of data are different, we are
sure that the two blocks are different. However, the reciprocal is not necessarly true,
and given a hash method there is a small chance to obtain the same hashcode on two
different blocks. The SFV-like file checking tools only generate one hashcode for
a whole file, which is surely enough to find out that a file is corrupted, but doesn't
allow for example to see that only the last 12KB of a 380MB file are corrupted.
This information might allow to retrieve only the corrupted data, which in most
cases is clearly faster than downloading the whole file once again.
AnFV enables you to create validation files for other files. These files contain
a set of hashcodes that allow to locate corrupted blocks within a bad file with a
customisable resolution. The block size can be reduced up to 256 bytes of data per
block. AnFV can still use the SFV format, but in that case it won't be able to tell
you where the errors are in a corrupted file.
Downloads: [ Windows ] |
 DriveSort v1.242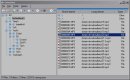
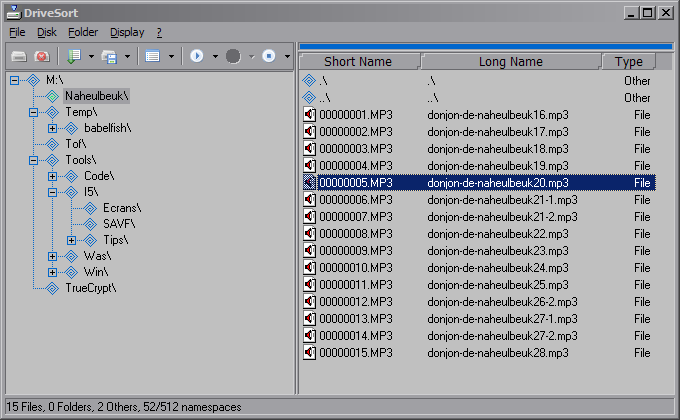
DriveSort sorts the directory tables of a volume formatted in FAT12, FAT16 or FAT32.
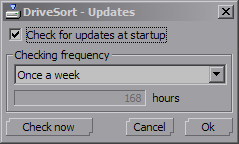
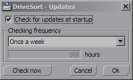
This sort orders the files on the disk according to a customizable order. Recent operating systems sort the files before showing them to the user, either by name, by size or by whatever the user choose.
However, it is not always the case in embedded OSes on small portable devices like MP3 players.
On these devices the lack of resources (CPU, memory) can lead their developers to make it display or play the files in the order in which they are on the disk.
This order depends mostly of the order in which they were added to the disk, which is not convenient for the user.
DriveSort can change this order to help such devices to play or view their files in the order you want, by putting them on the disk in a customizable order.
DriveSort sorts files and folders according to various options available in the popup menu next to the sort icon.
The order can then be saved to disk either folder by folder, or for all sub-folders.
- The comparison base:
- "Short name": sorts the files and directories according to the alphabetic order of their Short File Names [Default].
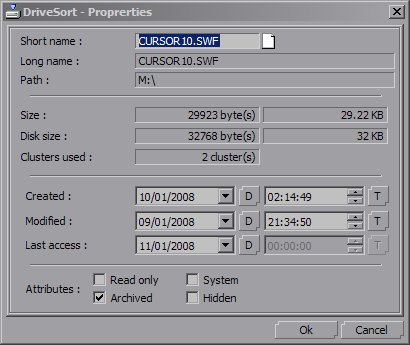
- ( A file or directory on a FAT volume always has a short file name,
which is the old MS-DOS 8.3 name format. It means that the name part of a filename must have at most eight characters, and its extension
at most three. A file or dir can also have a long file name, which can be a bit longer than 250 characters, and supports Unicode
characters. When a file name contains mixed case, or has one part that doesn't fit in the 8.3 convention, the file has both short and long filenames. )
- "Long Name": sorts the files and directories according to the alphabetic order of their Long File Names.
- "Logical Long Name": sorts the files and directories according to the alphabetic order of their Long File Names in a logical manner, that is by taking into account the numbers present in the names while sorting them.
- "File Size": sorts the files and folders according to their size on disk or for folders according to the sum of the sizes of all files and folders in the folder.
- "Creation Date": sorts the files and folders according to their creation date and time.
- "Access Date": sorts the files and folders according to their last access date (no time for this date in the FAT format).
- "Update Date": sorts the files and folders according to their last modification date and time.
- The sort direction: "Ascending" [Default] (aaaa.txt before aaab.txt) or "Descending" (aaab.txt before aaaa.txt)
- The position of folders relative to the files:
- "Before the files": Groups the folders together at the top of the name table, and sorts the files separately. [Default]
- "After the files": Groups the folders after the files, and sorts the files separately.
- "Mixed with files": No difference between files and folders, they are all sorted together.
- The recursive mode which sorts a folder and all its sub-folders by checking "Subdirectories".
DriveSort also features a manual ordering mode for files: the "playlist" mode, in which you can drag the files in the list in the order you want.
This mode is only available on the files having a long file name, because it alters the content of the short file name of the ordered files.
If it was used on a file having only a short file name, the name would be lost.
The short file name is altered to become something like "XXXXXXXX.EXT", where XXXXXXXX is the file's playlist number, and EXT is the file original extension.
The long file name of the files is not modified, and the files are automatically ordered on the disk using "Short Name" comparison.
This is particularly useful for multimedia players which play the songs using the short file name alphabetic order, and display them using their long file names, such
as the I-Bead, the Sony K750i, some devices for GBA/NDS...
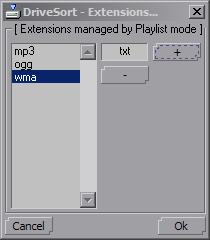
The playlist mode is initially able to move .MP3, .OGG and .WMA files around, to avoid files that are not really part of a playlist, like system files.
If you want to add other extensions to these, use the Extensions... menu in the playlist menu, or add them to the RecognizedExtensions option of the DriveSort.ini settings file.
DriveSort depends on the latest x86 Visual C++ redistributable components to run. When these are missing it will show an error message mentioning missing DLLs such as mfc140u.dll, vcruntime140.dll or some others with names like api-ms-win-crt-*.dll.
These are available for free from Microsoft and compatible with recent Windows versions (Windows XP to Windows 10).
On the most recent Windows versions these components are usually already deployed and kept up to date by Windows Update.
If you need to install them, you'll find the official installer for these components here:
[ vc_redist.x86.exe ] or in
the latest supported Visual C downloads.
NOTE: You'll need the x86 components even if you have a 64bit edition of Windows because DriveSort is compiled as a 32bit executable for compatibility reasons.
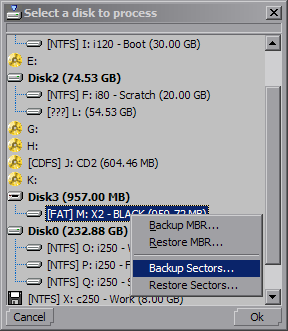
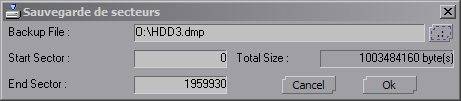
DriveSort works directly with the basic structures of the file-system, so be careful when using it, and backup anything important before.
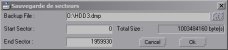
DriveSort can create a full backup of a disk or a partition from the disk selection dialog context menu.
Use this program at your own risks.
Screenshots: 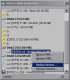
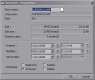
Latest news: [ v1.242 ]
[ v1.240 ]
[ v1.231 ]
[ v1.230 ]
[ v1.225 ]
[ Linux & Wine ]
[ v1.223 ]
[ v1.222 ]
Downloads: [ DriveSort (EN, Windows)  ] ] |
 jSAVF v1.83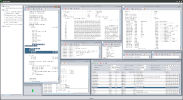
jSAVF enables you to consult the contents and check the integrity of an IBM
iSeries (AS/400) SAVF save file on a workstation with a recent Java runtime environment.
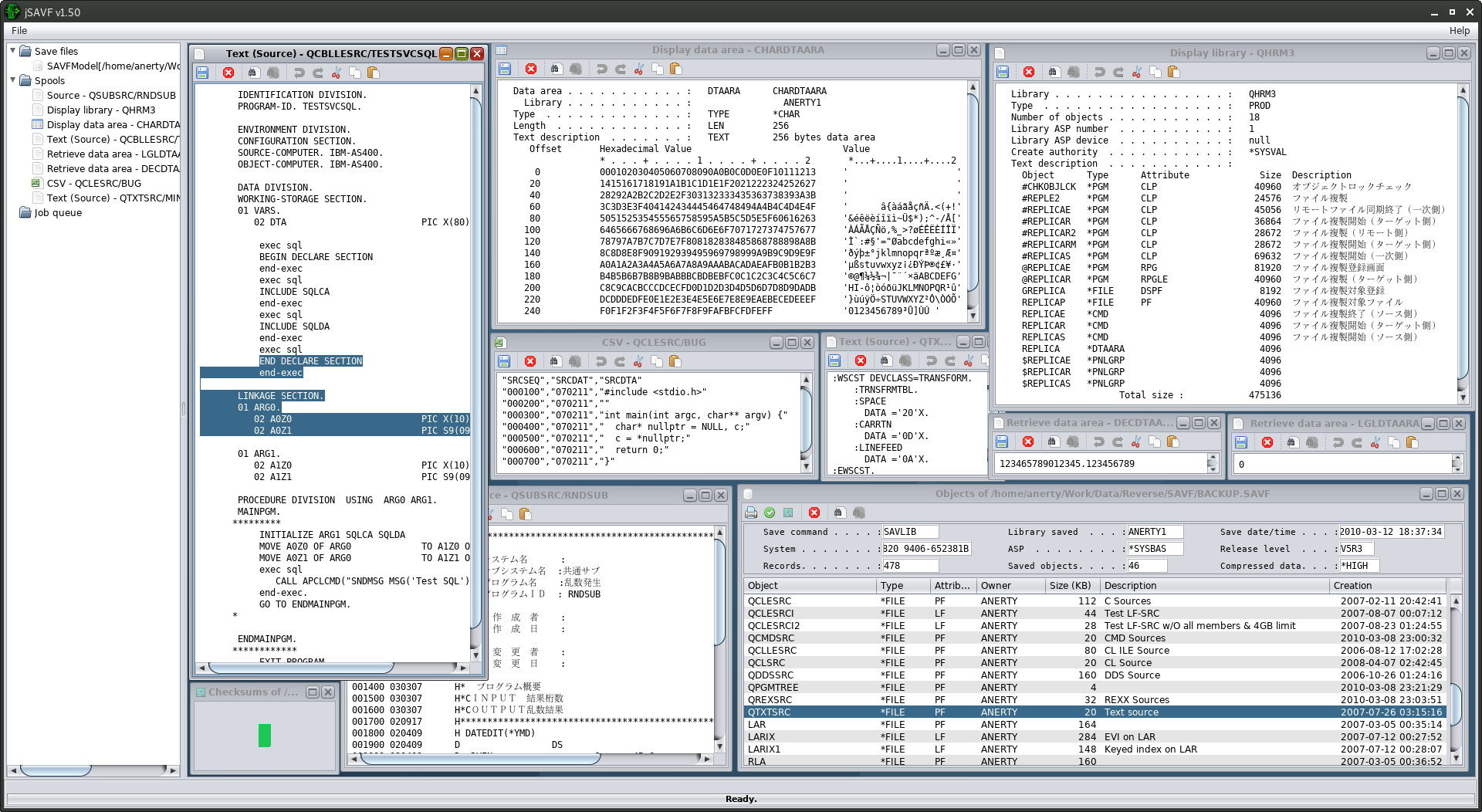
No connection to an iSeries is needed. jSAVF can open a save file (SAVF, ISO9660 or AWSTAPE magnetic tape image) with the menu or a drag-and-drop.
Once a save file is open, the objects are listed in a format similar to the one provided by the DSPSAVF command.
You can export this list to a text file using the Print menu in a format like the one provided by the DSPSAVF *PRINT command.
You can order the displayed objects by one or more criteria using the list headers and search them by name.
The SAVF file format analysis is done with a good hex editor and some info
found in the archive.midrange.com forum (particularly the two IBM proprietary checksum algotithms).
jSAVF supports either uncompressed SAVFs (*NO), those compressed with the old compression method (*YES before V5R3, *LOW since then), and those compressed with
the more recent methods (*MEDIUM, *HIGH, or zlib which seems to have appeared since V7R5).
The internal structure of some object types has been analysed so they can either be displayed in jSAVF as text spools, or exported as files.
- The objects of type *DTAARA (data areas) of all types (*CHAR, *DEC, *LGL) can be displayed or exported as text as the DSPDTAARA command would, or
more concisely as the RTVDTAARA command would.
- The objects of type *FILE with SAVF attribute (SAVF files) included within a SAVF can be exported as valid SAVF files, which can in turn be opened
by jSAVF.
- The data in objects of type *STMF in IFS save files can be exported without conversion.
- The source members of objects of type *FILE with PF attribute (source physical files such as QCBLLESRC, QCLLESRC, QCLESRC, QRPGLESRC, QSQLLESRC,
...) can be exported as text, source or CSV format:
- The source format exports the SRCSEQ, SRCDAT and SRCDTA fields separated by one space, without truncating trailing whitespace.
- The CSV format exports these three fields surrounded by double quotes, separated by commas, without trailing whitespace, and escapes any double quote inside
a field by doubling it.
- The text format only exports the SRCDTA field without trailing whitespace.
For files whose field CCSID doesn't match the field contents (corrupted accents or special characters), it's possible to force the use of the default CCSID
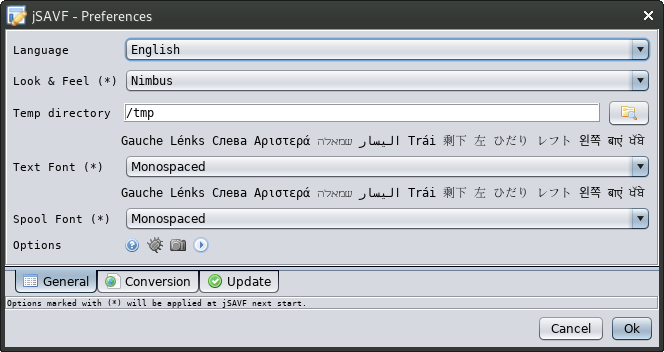
configured in the file/preferences dialog to ensure jSAVF reads the source data correctly.
Source files are always exported as UTF-8 by jSAVF.
- The contents of database tables or non-source physical file members are exportable as CSV:
- Fields of the following types are supported: NUMERIC, DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, REAL, DOUBLE, DATE, TIME, TIMESTAMP, CHAR, BINARY, VARCHAR, VARBINARY, GRAPHIC, VARGRAPHIC, DBCS, CLOB, BLOB, DBCLOB, ROWID
- NULL field values are exported without double quotes surrounding them.
- Depending on the format, it is possible that some text fields are incorrectly decoded when jSAVF can't figure out their encoding.
- Tables with large values in CLOB or BLOB fields will possible not be exportable completely. BLOB field values are exported as hexadecimal strings.
- ROWID fields won't be exported correctly unless they're defined with REFSHIFT(H).
- Experimentally, the contents of *SOURCE or *LIST debug views included in some objects of type *PGM, *MODULE, *SRVPGM during compilation, and the source of some CLP programs which include them.
- The analysis of the other types is ongoing, meanwhile the raw objects and members can be exported.
The integrity checks performed by jSAVF are:
- The file size is validated against the SAVF header information, to ensure it is not truncated.
- The blocks read by jSAVF are checked against the block checksums in the SAVF. jSAVF will therefore control the integrity of part of the SAVF during
its indexing, and will also control the blocs required to display or export the objects you chose to display or export.
- There is also a menu allowing you to verify the integrity of all SAVF blocs at once, and the global file checksum.
Prerequisites
- The data conversions between EBCDIC and Unicode require some Java codepages which are optional in some JRE versions. If you install a JRE, ensure
you check every install option, otherwise some SAVF might not be readable.
- jSAVF needs OpenJDK 25 or above, its Windows installer includes a minimal modular image of it.
If you are on Linux or already have one somewhere you can download the smaller jSAVF archive instead of the installer to save bandwidth.
Limits
- jSAVF has limited support of SAVF generated on the IFS filesystem (SAV command)
- jSAVF can sometimes fail to read SAVF generated either with exotic SAV* commands or by very old OS/400 releases.
If you find issues in jSAVF you can reach out to me to solve them, but please don't send me any save file without clearing it first with the system owners and stakeholders for confidentiality and security reasons. Also please don't send me any save file without discussing it with me first.
Screenshots:
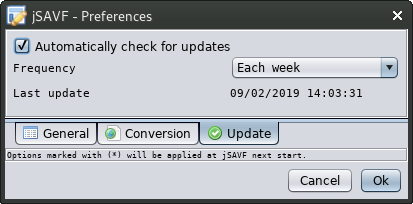
Latest news: [ v1.83 ]
[ v1.82 ]
[ v1.81 ]
[ v1.80 ]
[ v1.72 ]
[ v1.71 ]
[ v1.70 ]
[ v1.60 ]
[ v1.51 ]
[ v1.50 ]
[ v1.40 ]
[ v1.32 ]
[ v1.31 ]
[ v1.30 ]
Downloads: [ jSAVF (1 MiB, Linux JARs only) ] [ jSAVF (1 MiB, Windows JARs only) ] [ jSAVF (32 MiB, Windows Installer, includes OpenJDK 25.0.1+8 x64) ] |
|
Style: [ intro ] [ full ] |


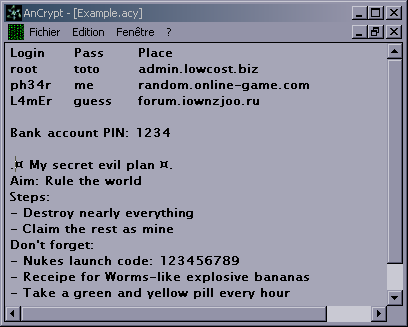 AnCrypt is a Notepad-like text editor which crypts the edited files (BlowFish 448bit algorithm).
It can be used to carry confidential data on an USB key.
AnCrypt is a Notepad-like text editor which crypts the edited files (BlowFish 448bit algorithm).
It can be used to carry confidential data on an USB key.