

AnFV v1.0
 AnFV enables you to perform advanced integrity check on files.
Unlike many other similar softwares, AnFV pinpoints the location and extent
of one or more erroneous blocks in a checked file.
AnFV enables you to perform advanced integrity check on files.
Unlike many other similar softwares, AnFV pinpoints the location and extent
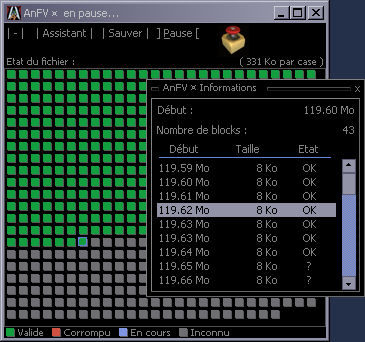
of one or more erroneous blocks in a checked file.The easiest way to check that a file is the same as an original is certainly to compare it byte by byte to the original. However, when the original is not available on site, for example in the case of a downloaded file, it is impossible to do so without having to download it once again. In this case, the most widespread method to check that a file is not corrupted is to compute a kind of magical number for the original file, and to compare it to the one computed for the downloaded one.
This kind of computation is called hashing, and the magical number is a hashcode. There are plenty of ways to hash data, amongst which we find the well-known CRC-32, MD5 and SHA1. If the hashcodes obtained on two blocks of data are different, we are sure that the two blocks are different. However, the reciprocal is not necessarly true, and given a hash method there is a small chance to obtain the same hashcode on two different blocks. The SFV-like file checking tools only generate one hashcode for a whole file, which is surely enough to find out that a file is corrupted, but doesn't allow for example to see that only the last 12KB of a 380MB file are corrupted. This information might allow to retrieve only the corrupted data, which in most cases is clearly faster than downloading the whole file once again.
AnFV enables you to create validation files for other files. These files contain a set of hashcodes that allow to locate corrupted blocks within a bad file with a customisable resolution. The block size can be reduced up to 256 bytes of data per block. AnFV can still use the SFV format, but in that case it won't be able to tell you where the errors are in a corrupted file.
Downloads: [ Windows ]